
这一次我终于可以开始真正的深度学习了,从一个神经网络开始。
神经网络(Neural Network)是深度学习的基础,基本概念包括:神经元,层,反向传播等等。如果细讲我估计没有五到十篇文章那是讲不完的。简单说它模拟了大脑神经元工作的方式,利用把多个神经元组合成网络结构的模型来对数据进行分类。
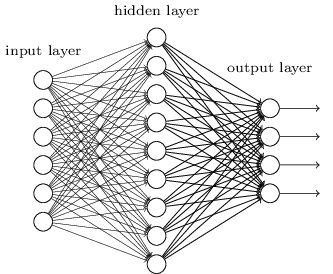
- 神经网络是一个多层结构的反馈网络,包括输入,输出和隐藏层。
- 每一层由若干个神经元组成。
- 整个网络利用反向传播,反馈输出的结果和期望值的差异来进行学习。
- 可以理解网络是一个函数ouput=function(input), 随着网络层次的加深,神经网络可以模拟一个非常复杂的非线性函数,当然学习的成本就更高,因为要学习的参数会随着层数和每一层的神经元的个数增加而增加。
TensorFlowJs提供了对神经网络/深度神经网络提供了很好的支持。包括:模型 tf.model, 层 tf.layer。
下面我们就看看如果利用TensorFlowJS来构建一个简单的神经网络来进行MINST数据的手写识别。
构建网络
function nn_model() { const model = tf.sequential(); model.add(tf.layers.dense({ units: 32, inputShape: [784] })); model.add(tf.layers.dense({ units: 256 })); model.add(tf.layers.dense( {units: 10, kernelInitializer: 'varianceScaling', activation: 'softmax'})); return model;} 以上代码构建了一个有两个隐藏层的神经网络,第一层有32个神经元,第二层有256个神经元。
-
tf.sequential 构建一个序列化的网络模型,这样的网络每一层的输出连接到下一层的输入,类似一个有每一层组成的栈。不存在分支或者跳跃。
-
利用model.add向模型中增加一层
-
tf.layers.dense提供一个全联接的层。units定义了该层的神经元个数。inputShape是输入数据的形状。网络中第一层必须明确指定输入形状,其余的层默认从前面的层输入。
-
最后一层决定了分类器的结果,所以我们使用softmax作为激活函数,units为10,表示10的数字0-9的分类结果。
网络初始化
const model = nn_model();const LEARNING_RATE = 0.15;const optimizer = tf.train.sgd(LEARNING_RATE);model.compile({ optimizer: optimizer, loss: 'categoricalCrossentropy', metrics: ['accuracy'],}); - 初始化模型,定义学习率,优化器
- 调用model.compile方法,定义损失函数。
训练网络
async function train() { const BATCH_SIZE = 16; const TRAIN_BATCHES = 100; const TEST_BATCH_SIZE = 100; const TEST_ITERATION_FREQUENCY = 5; for (let i = 0; i < TRAIN_BATCHES; i++) { const batch = data.nextTrainBatch(BATCH_SIZE); let testBatch; let validationData; // Every few batches test the accuracy of the mode. if (i % TEST_ITERATION_FREQUENCY === 0 && i > 0 ) { testBatch = data.nextTestBatch(TEST_BATCH_SIZE); validationData = [ testBatch.xs.reshape([TEST_BATCH_SIZE, 784]), testBatch.labels ]; } // The entire dataset doesn't fit into memory so we call fit repeatedly // with batches. const history = await model.fit( batch.xs.reshape([BATCH_SIZE, 784]), batch.labels, {batchSize: BATCH_SIZE, validationData, epochs: 1}); batch.xs.dispose(); batch.labels.dispose(); if (testBatch != null) { testBatch.xs.dispose(); testBatch.labels.dispose(); } await tf.nextFrame(); }} - 训练的核心方法是调用model.fit(x,y,config)方法。x是训练数据,y是训练的分类标签。config是可选项。
- 在训练过程中,我们使用testBactch来做验证,计算准确率。结果存入model.fit的返回值中。
- 调用dispose方法释放tensor占用的内存
- tf.nextFrame() 返回一个Promise,主要用于Web动画。
static nextFrame(): Promise
{ return new Promise (resolve => requestAnimationFrame(() => resolve()));}
大家可以试一试我在。
通过改变模型的层数和每一层神经元的个数,我们可以评估该模型是否有效。
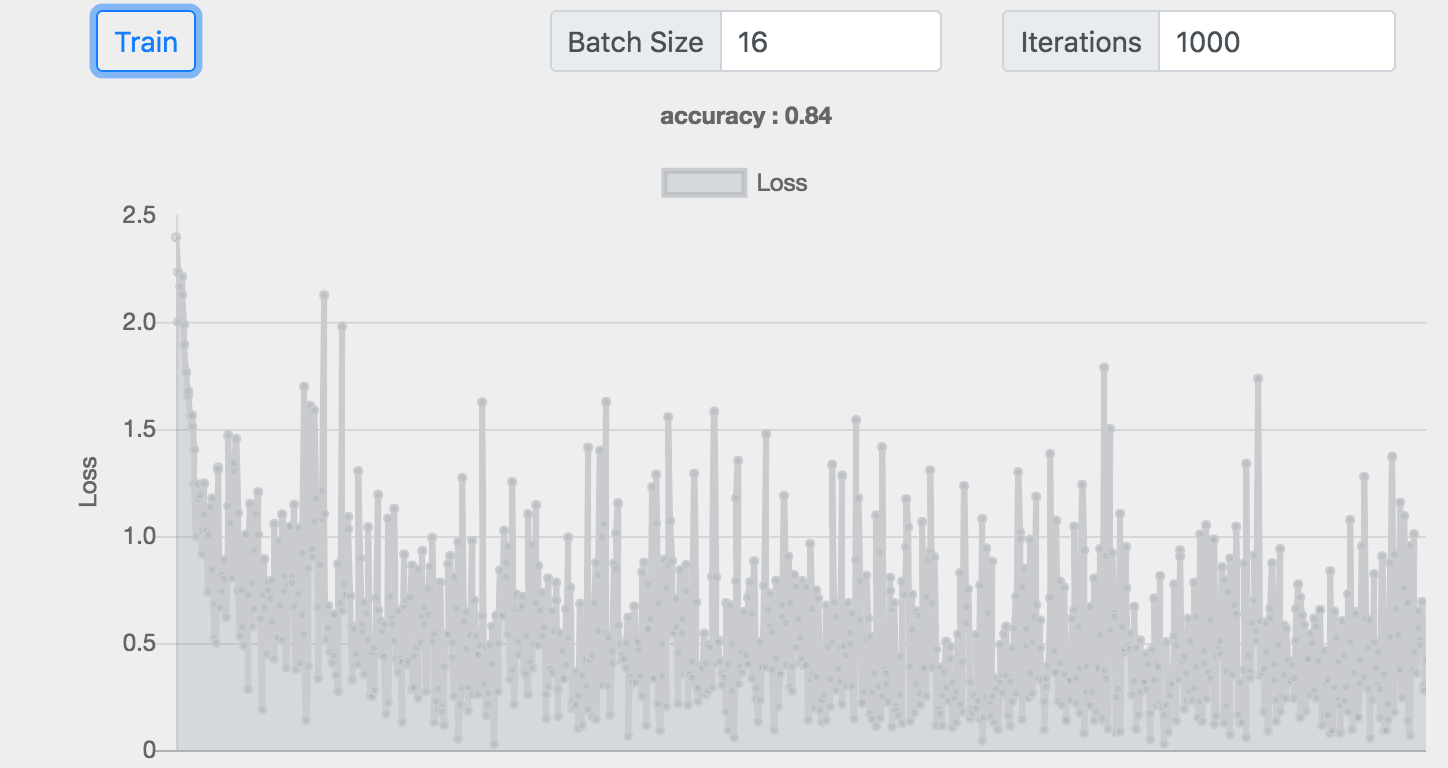
Batch :16 神经元 :32+256 准确率 :0.84
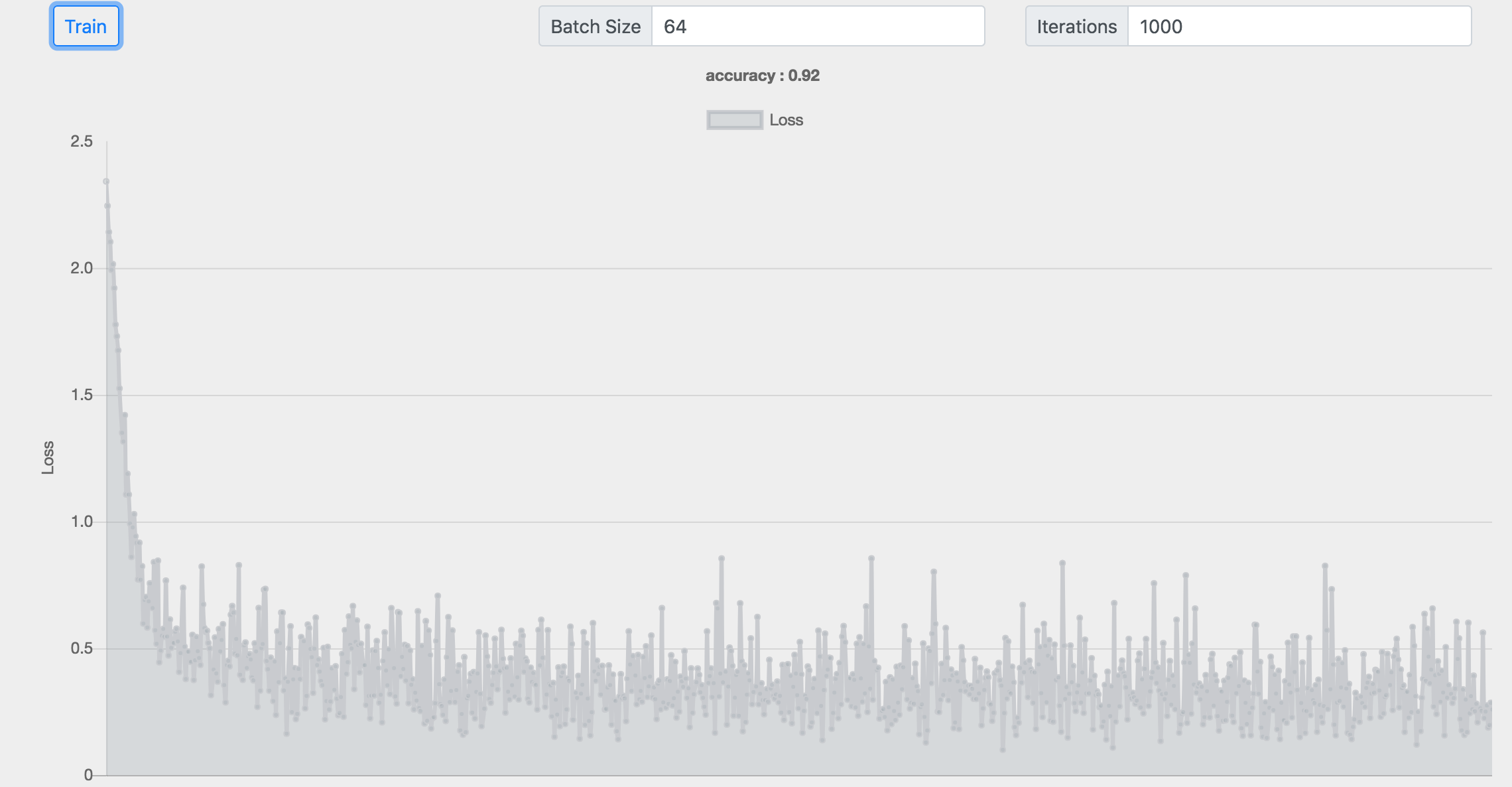
Batch :64 神经元 :32+256 准确率 :0.92
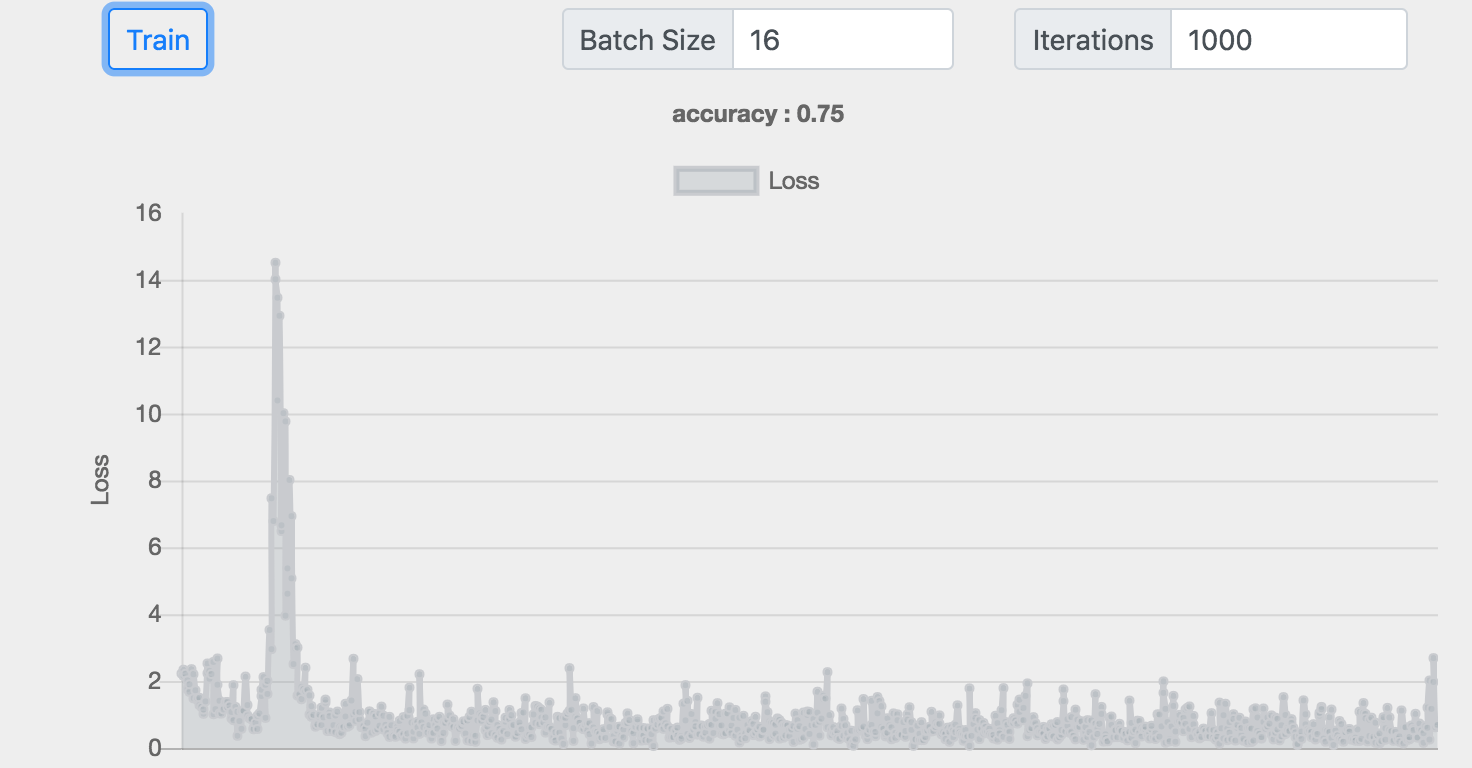
Batch :16 神经元 :32+256+256+32 准确率 :0.75
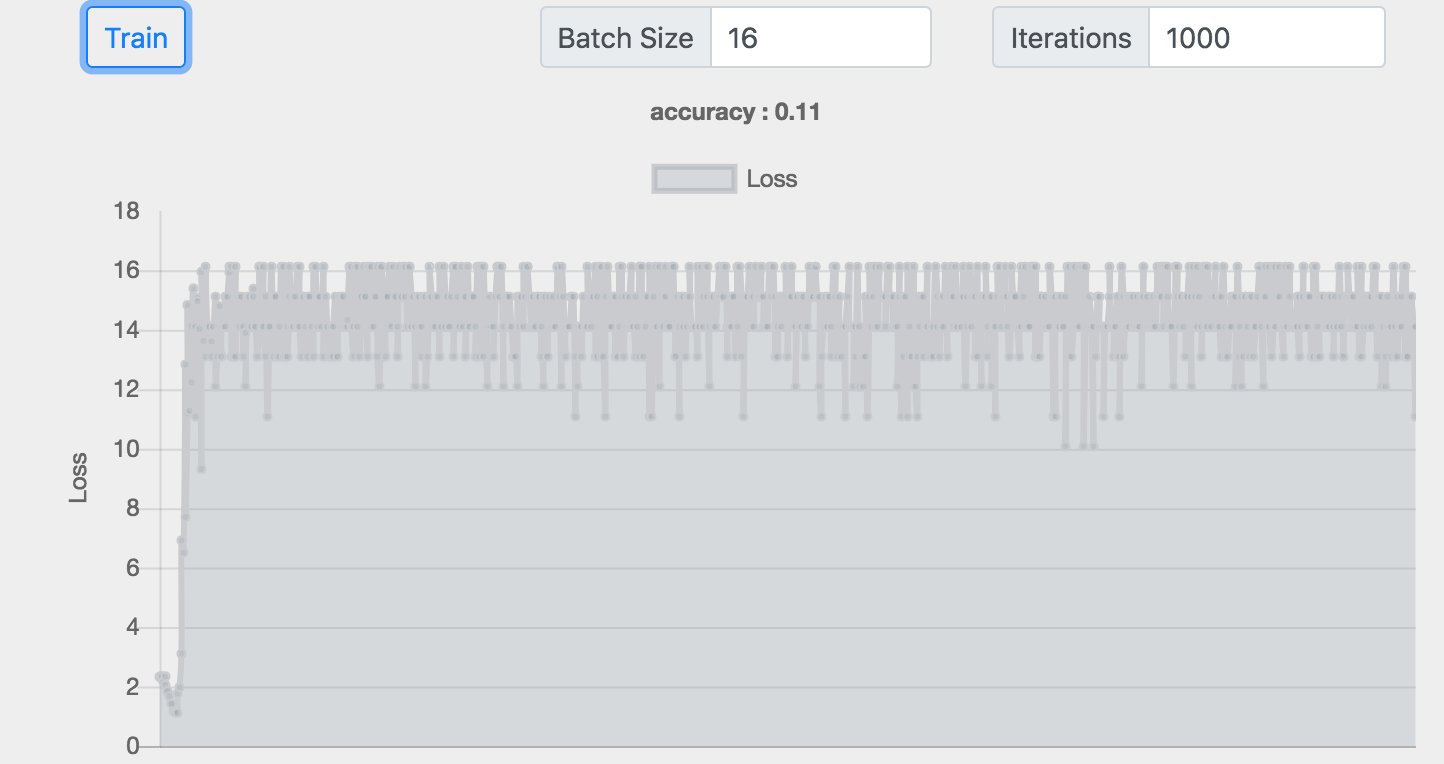
Batch :16 神经元 :32+256+256+256 准确率 :0.11
我们发现网络也并非越深越好,在最后一个4层的例子中,训练的损失很高,效果很差。
在深度学习中如果定义这些超参数(),真的很难。
较大的batchSize效果比较小的要好,但是由于浏览器内存的限制,我们无法加载较大的Batch训练数据。
更多的发现留给大家去尝试。
神经网络的种类有很多,以后有机会我们可以继续了解。
参考:
- 知乎:
-
阮一峰的网络日志: